𝑪𝒉𝒆𝒏𝒈 𝑯𝒖𝒂𝒏𝒈, 𝑷𝒉.𝑫. 🍊
🚀 I got my doctoral degree degree from Southern Methodist University (SMU) on November 18, 2025. I am the first and also currently the only person in SMU history to complete the Ph.D. program in just two years! Prior to that, I got my master's degree from the Chinese University of Hong Kong (CUHK) in 2022. And I obtained the bachelor's degree from University of Electronic Science and Technology of China (UESTC) in 2020.
✨✨✨ I am currently on the job market and welcome any opportunities or discussions. Please feel free to reach out if there is a potential fit. ✨✨✨
My research interests mainly focus on developing biomarker-driven multimodal AI systems for clinical decision support and disease progression modeling, specifically: Medical AI -> Developing multimodal models for diagnosis and clinical decision support, integrating diverse medical data.
-
By the way, I also conduct research in the following areas:
- AI for Finance: Designing data-centric models for risk analysis and anomaly detection, leveraging large-scale structured and temporal financial data.
- Neuromorphic Computing: Exploring next-generation computing paradigms to enable efficient and scalable intelligent systems.
My long-term vision is to advance AI for Health Care by building clinically grounded, trustworthy, and multimodal intelligence systems. I frame this mission through the Hippocrates paradigm:
(1) Biomarker Intelligence
Discovering disease-specific biomarkers from multimodal medical data, like fundus, OCT, OCTA, and clinical metadata—through robust and interpretable AI.
(2) Clinically Aligned Generation
Developing multimodal report-generation and decision-support models that integrate imaging, physiology, and language to produce clinically reliable outputs.
(3) Autonomous Diagnostic Systems
Building agentic medical AI systems with reasoning, memory, and self-improving capabilities to support longitudinal disease progression modeling and early intervention.
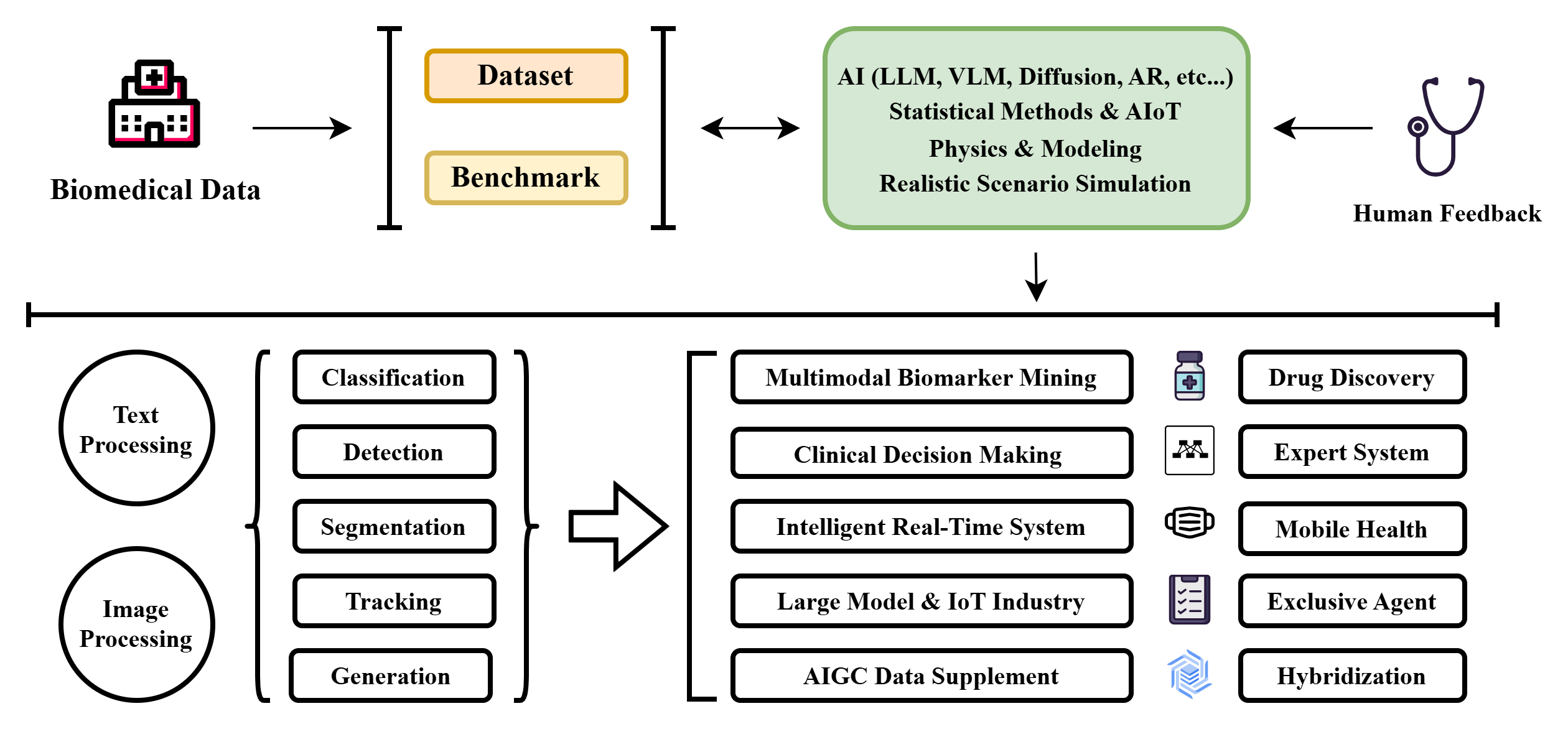
Research Map: The Schematic Overview of My Research Vision
News
- [2026/05] 2 papers was accepted by IEEE PRAI!
- [2026/04]🔥🔥🔥 3 papers was accepted by IEEE 48th EMBC!
- [2026/01]🔥🔥🔥 1 paper was accepted by IEEE 51st ICASSP!
- [2026/01] 1 paper was accepted by BNNIO 2026!
- [2025/11]🥳🥳🥳 I successfully defended Ph.D. dissertation.
- [2025/11]🥳🥳🥳 I have been nominated to attend the Nobel Prize and its conference!
- [2025/10]🔥🔥🔥 We have just released the survey: Tibetan Language and AI: A Comprehensive Survey of Resources, Methods and Challenges.
- [2025/09]1 paper was accepted by IEEE 25th BIBE!
- [2025/08]🚀🚀🚀 1 paper was accepted by EMNLP 2025!
- [2025/07]🔥🔥🔥 1 paper was accepted by ICONIP 2025!
- [2025/05]🥳🥳🥳 I was selected as the outstanding graduate student of the Department of computer science!
- [2025/05]🥳🥳🥳 I passed my mid-term PhD defense!
- [2025/04]🔥🔥🔥 2 papers are accepted by IEEE 47th EMBC
- [2025/03]1 paper is accepted by IEEE Journal of Systems Engineering and Electronics!
- [2024/11]🥳🥳🥳 I have passed my Ph.D. qualifying exams and am now a Ph.D. candidate rather than a Ph.D. student.
- [2024/11]1 paper is accepted by IEEE ICNC 2024.
- [2023/12]🔥🔥🔥 2 papers are accepted by AAAI 2024 and its Workshop.
- [2023/12]1 paper is accepted by Applied and Computational Engineering and is selected as the cover paper.
- [2023/08]🚀🚀🚀 Book "Neuromorphic Circuits for Nanoscale Devices" has been published (ISBN: 9787111704119).
- [2023/07]🔥🔥🔥 1 paper is accepted by IEEE ICTAI 2023.
- [2022/12]I have officially graduated with my master's degree!
- [2022/12]1 paper is accepted by Biomedical Signal Processing and Control.
- [2022/05]🚀🚀🚀 1 paper is accepted by IEEE Transactions on Instrumentation and Measurement and is selected as the cover paper.
- [2021/06]🚀🚀🚀 2 papers are accepted by IEEE PRAI 2021 and both of them won the Excellent Presentation Award.
- [2020/08]1 paper is accepted by IEEE CDS 2020.
- [2020/07]1 paper is accepted by IEEE ICVRV 2020.
- [2020/07]1 paper is accepted by ACM ICRAI 2020.
- [2020/06]I have officially graduated with my bachelor's degree!
- [2020/06]🥳🥳🥳 My undergraduate thesis was selected as an Outstanding Undergraduate Thesis (5/710).
- [2020/05]🔥🔥🔥 1 paper is accepted by IEEE 20th ICCT 2020.
Education

Southern Methodist University, USA
Ph.D. Degree in Computer Science • Sep. 2023 - Dec. 2025
Advisor: Prof. Jia Zhang Research Direction: AI for Diagnosis & Treatment of Glaucoma based Biomarker
Advisor: Prof. Jia Zhang Research Direction: AI for Diagnosis & Treatment of Glaucoma based Biomarker

The Chinese University of Hong Kong, Hong Kong
Master Degree in Information Engineering • Sep. 2021 - Dec. 2022
Advisor: Prof. John Kar-Kin Zao Research Direction: AIoT for Public Health
Advisor: Prof. John Kar-Kin Zao Research Direction: AIoT for Public Health

University of Electronic Science and Technology of China, China
Bachelor Degree in Information Engineering • Sep. 2016 - Jun. 2020
Advisor: Prof. Yongbin Yu Research Direction: Medical Imaging in Skin Lesion
Advisor: Prof. Yongbin Yu Research Direction: Medical Imaging in Skin Lesion
Work & Research

University of Texas Southwestern Medical Center, USA
Postdoctoral Fellow • Jun. 2026 - Now
Advisor: Prof. Guanghua Xiao and Prof. Yang Xie Research Direction: AI for Health Care
Advisor: Prof. Guanghua Xiao and Prof. Yang Xie Research Direction: AI for Health Care

Mount Sinai Hospital, USA
Research Associate • Jun. 2026 - Now
Advisor: Prof. Jason J. Liu Research Direction: AI for Digital Health & Genomics
Advisor: Prof. Jason J. Liu Research Direction: AI for Digital Health & Genomics

Decode Origin, USA
Bioinformatics Scientist (Remote) • Apr. 2026 - Jun. 2026
Research Direction: Data Curation for Life Science
Research Direction: Data Curation for Life Science

ZenWeave AI, USA
Senior Research Scientist • Jan. 2026 - Now
Collaboration: Dr. Yadi Liu and Jingxi Qiu Research Direction: AI for Finance
Collaboration: Dr. Yadi Liu and Jingxi Qiu Research Direction: AI for Finance

National Aeronautics and Space Administration, USA
Research Fellow • Jan. 2024 - Dec. 2025
Advisor: Dr. Tsengdar Lee Research Direction: Medical AI
Advisor: Dr. Tsengdar Lee Research Direction: Medical AI
University of Texas Southwestern Medical Center, USA
Research Scientist • Jun. 2024 - Aug. 2024
Advisor: Dr. Karanjit Kooner & Prof. Jui-Kai Wang Research Direction: Medical Imaging in Glaucoma
Advisor: Dr. Karanjit Kooner & Prof. Jui-Kai Wang Research Direction: Medical Imaging in Glaucoma
Southern Methodist University, USA
Teaching Assistant (CS 2341, Data Structure) • Aug. 2023 - Dec. 2023
Supervisor: Prof. Michael Hahsler
Supervisor: Prof. Michael Hahsler

Tsinghua University, China
Research Associate • Mar. 2021 - Jul. 2021
Advisor: Prof. Huazhong Yang & Prof. Lu Zhang Research Direction: AI Chips Design, Electronic Design Automation
Advisor: Prof. Huazhong Yang & Prof. Lu Zhang Research Direction: AI Chips Design, Electronic Design Automation

Sichuan Jiuzhou Prevention and Control Technology Co., Ltd., China
Computer Engineer • Jan. 2020 - May. 2020
Project: Remote Sensing
Project: Remote Sensing

Sichuan Electric Power Design & Consulting Co.,Ltd., China
Communication Telecontrol Designer • Jan. 2019 - Jul. 2019
Project: 5G Station Development
Project: 5G Station Development
Interview & Talk

From Digital Clones to Next-Generation AI Systems
Talk • Time: 01/17/2026, 16:30 pm - 18:00 pm, BJT
Location: Building 16, No. 10 Xibeiwang East Road, Beijing 100193, China (SoftStone Group Headquarters)
Location: Building 16, No. 10 Xibeiwang East Road, Beijing 100193, China (SoftStone Group Headquarters)

Large Language Model & Medical AI Agent
Talk • Time: 01/16/2026, 15:30 pm - 17:30 pm, BJT
Location: East Tower, Building 1, No. 6 Weigongcun Road, Haidian District, Beijing 100081, China (Ant T Space)
Location: East Tower, Building 1, No. 6 Weigongcun Road, Haidian District, Beijing 100081, China (Ant T Space)

Digital Agents & Financial AI
Talk • Time: 01/14/2026, 14:30 pm - 16:00 pm, BJT
Location: Hangyu Building, No. 20 Financial Street, Beijing 100032, China (E-Fund Management Co., Ltd.)
Location: Hangyu Building, No. 20 Financial Street, Beijing 100032, China (E-Fund Management Co., Ltd.)

Tibetan Language Processing & Modeling
Interview • Time: 09/12/2025, 17:00 pm - 18:30 pm, CT
Location: 225 North Avenue NW, Atlanta, GA 30332, USA (Georgia Institute of Technology)
Location: 225 North Avenue NW, Atlanta, GA 30332, USA (Georgia Institute of Technology)
Academic Service
- Chair: IEEE PRAI'25/26
- Committee: IEEE PRAI'25/26, AAAI'26/27
- Conference Reviewer: CVPR'25/26, MICCAI'25/26, ICME'25/26, IEEE PRAI'25/26, IEEE BIBE'25, ICONIP'25, IEEE EMBC'26, AAAI'26/27, NLPCC'26
- Journal Reviewer: IEEE Journal of Translational Engineering in Health and Medicine, American Journal of Diagnostic Imaging, Journal of Computer Sciences and Informatics, The Journal of Supercomputing, Digital Health, IEEE Journal of Biomedical and Health Informatics
Principal Investigator
Project: Federated Learning Alignment Method under Multi-Type Data Distribution (2022KQNCX084)
Category: Guangdong Province Higher Education Youth Innovation Talent Project - Natural Science
Role: Co-PI, with Dr. Siyang Jiang
Description: A study on developing alignment methods in federated learning to address challenges posed by heterogeneous data distributions across clients, including differences in features, labels, and modalities.
Personal Interests
- Anime: Dragon Ball series
- Hobby: Skiing, Fitness, Off-Roading, Hunting, Traveling
- Motto: 我还在寻找属于我自己的那朵花...至少现在是这样的。


My hometown is Guangan, Sichuan China, you can call me nickname: Yellow Orange.
Last updated on April, 2026
Template inspired by Jon Barron.